The Power of Unstructured Text Mining
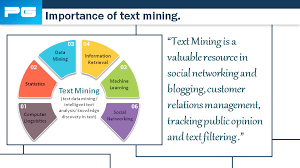
Unstructured text mining is a powerful tool that allows us to extract valuable insights and information from unstructured data sources such as emails, social media posts, news articles, and more. Unlike structured data, which is neatly organised in databases or spreadsheets, unstructured data is raw and untamed, making it challenging to analyse.
With the help of advanced natural language processing (NLP) techniques and machine learning algorithms, unstructured text mining enables us to uncover patterns, trends, and hidden knowledge within vast amounts of textual data. By processing and analysing this unstructured text, we can gain valuable insights into customer sentiment, market trends, emerging topics, and much more.
Organisations across various industries are leveraging unstructured text mining to improve customer service, enhance decision-making processes, detect fraud, predict market trends, and even advance scientific research. By harnessing the power of unstructured text mining, businesses can unlock new opportunities for growth and innovation.
However, working with unstructured text data comes with its own set of challenges. Cleaning and preprocessing the data, dealing with noise and ambiguity in the text, and ensuring the accuracy of the analysis are all critical steps in the unstructured text mining process. It requires a combination of domain expertise, technical skills, and creativity to extract meaningful insights from unstructured data effectively.
In conclusion, unstructured text mining offers a wealth of opportunities for businesses and researchers to extract valuable insights from vast amounts of textual data. By leveraging advanced technologies and analytical tools, we can uncover hidden patterns and trends that can drive innovation and success in today’s data-driven world.
Five Essential Techniques for Effective Unstructured Text Mining
- Preprocess the text data by removing stopwords, punctuation, and special characters.
- Tokenize the text into words or phrases to analyse them individually.
- Use techniques like stemming or lemmatization to reduce words to their base form for better analysis.
- Apply methods such as TF-IDF or word embeddings to represent the text data numerically for modelling.
- Utilize topic modelling algorithms like LDA or NMF to extract themes and patterns from unstructured text.
Preprocess the text data by removing stopwords, punctuation, and special characters.
In the realm of unstructured text mining, a crucial tip is to preprocess the text data meticulously by eliminating stopwords, punctuation marks, and special characters. By removing these elements that do not carry significant meaning or contribute to the analysis, we can streamline the text for more effective processing and analysis. This preprocessing step not only helps in reducing noise within the data but also enhances the accuracy and efficiency of extracting valuable insights from unstructured text sources.
Tokenize the text into words or phrases to analyse them individually.
In the realm of unstructured text mining, a crucial tip is to tokenize the text into words or phrases before analysis. By breaking down the raw text into smaller units such as words or phrases, we can analyse and understand each component individually. This process of tokenization enables us to extract key information, identify patterns, and uncover insights hidden within the text data. Tokenizing the text lays the foundation for further analysis and allows for a more detailed exploration of the textual content, ultimately leading to more accurate and meaningful results in unstructured text mining tasks.
Use techniques like stemming or lemmatization to reduce words to their base form for better analysis.
Utilising techniques such as stemming or lemmatization in unstructured text mining can significantly enhance the analysis process by reducing words to their base form. By transforming words into their root or base form, we can consolidate variations of the same word, thus improving the accuracy and efficiency of text analysis. This approach helps in uncovering underlying patterns and extracting meaningful insights from unstructured data, ultimately leading to more robust and reliable results in text mining endeavours.
Apply methods such as TF-IDF or word embeddings to represent the text data numerically for modelling.
To enhance the effectiveness of unstructured text mining, it is recommended to apply methods such as TF-IDF (Term Frequency-Inverse Document Frequency) or word embeddings to represent the text data numerically for modelling. By utilising these techniques, we can transform raw textual information into numerical vectors that machine learning algorithms can process effectively. TF-IDF assigns weights to words based on their frequency in a document and across a corpus, capturing their importance in context. On the other hand, word embeddings map words into dense vector representations in a continuous vector space, preserving semantic relationships between words. Incorporating these methods in text mining enables more accurate and meaningful analysis of unstructured data, leading to valuable insights and informed decision-making.
Utilize topic modelling algorithms like LDA or NMF to extract themes and patterns from unstructured text.
To enhance the efficiency and effectiveness of unstructured text mining, it is recommended to utilise topic modelling algorithms such as Latent Dirichlet Allocation (LDA) or Non-Negative Matrix Factorization (NMF). These advanced algorithms enable the extraction of underlying themes and patterns from unstructured text data, allowing researchers and businesses to uncover valuable insights and trends that may not be immediately apparent. By applying LDA or NMF in the analysis process, organisations can gain a deeper understanding of their textual data, identify key topics, and make more informed decisions based on the extracted themes.
No Responses