Time Series Data Mining: Unveiling the Patterns of Time
In today’s data-driven world, the amount of information generated is growing at an unprecedented rate. Amongst this vast sea of data, time series data holds a special place. Time series data refers to a sequence of observations collected over time, where each observation is associated with a specific timestamp. This type of data can be found in various domains such as finance, healthcare, weather forecasting, and many more.
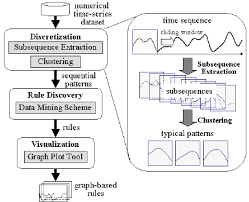
Time series data mining is the process of extracting meaningful patterns and insights from these temporal sequences. It involves analyzing the past observations to make predictions or uncover hidden patterns that can aid decision-making in various domains.
One of the primary objectives of time series data mining is forecasting. By analyzing historical patterns and trends, we can make predictions about future values or events. This has proven to be invaluable in numerous fields such as stock market analysis, demand forecasting, and predicting disease outbreaks.
Another important aspect of time series data mining is anomaly detection. Anomalies are observations that deviate significantly from the expected behavior or pattern. By detecting anomalies in time series data, we can identify potential errors, faults, or unusual events that require attention. This has applications in fraud detection, network security monitoring, and predictive maintenance.
Furthermore, time series data mining allows us to uncover recurring patterns and dependencies within the temporal sequences. These patterns can provide valuable insights into underlying processes and relationships. For example, in climate research, analyzing long-term weather patterns helps us understand climate change dynamics.
To effectively mine time series data, various techniques and algorithms have been developed. These include statistical methods like autoregressive integrated moving average (ARIMA), exponential smoothing (ETS), and seasonal decomposition of time series (STL). Machine learning algorithms such as support vector machines (SVM), random forests (RF), recurrent neural networks (RNN), and long short-term memory networks (LSTM) are also commonly used.
However, time series data mining comes with its own set of challenges. The temporal nature of the data introduces complexities such as seasonality, trend, and non-stationarity. Additionally, missing values, noise, and outliers can further complicate the analysis. Therefore, careful preprocessing and feature engineering are crucial to ensure accurate results.
In conclusion, time series data mining plays a vital role in uncovering the hidden patterns and insights within temporal sequences. It enables us to make predictions, detect anomalies, and understand underlying processes. With the ever-increasing availability of time series data, advancements in this field will continue to drive innovation across various domains. As we delve deeper into the realm of time, we unlock the power to anticipate and shape our future based on the patterns of our past.
6 Essential Tips for Time Series Data Mining
- Understand the data
- Use appropriate algorithms
- Implement proper pre-processing steps
- Consider using a sliding window approach
- Utilize ensemble methods
- Monitor performance metrics
Understand the data
When it comes to time series data mining, one of the most important tips to keep in mind is to thoroughly understand the data you are working with. Time series data can be complex and dynamic, so taking the time to gain a deep understanding of its characteristics is crucial for successful analysis.
First and foremost, familiarize yourself with the temporal aspect of the data. Understand the frequency at which observations are recorded and whether there are any gaps or irregularities in the timestamps. This will help you determine how to handle missing values and ensure that your analysis captures the true temporal patterns.
Next, explore the trends and seasonality present in the data. Look for any long-term trends or recurring patterns that may influence future values. Identifying seasonality can also provide valuable insights into cyclical patterns that may impact your analysis.
Furthermore, examine any outliers or anomalies within the time series. These aberrations can significantly affect your models and predictions, so it’s crucial to understand their causes and decide how to handle them appropriately. Determine whether they are genuine anomalies or errors in data collection.
Additionally, consider other relevant factors that may influence the time series data. Are there external variables such as weather conditions or economic indicators that could impact your analysis? Understanding these contextual factors will help you build more accurate models and make more informed predictions.
Lastly, assess the quality of your data. Look for potential issues such as noise, errors, or biases that could affect your results. Cleaning and preprocessing the data may be necessary before diving into complex modelling techniques.
By taking the time to truly understand your time series data, you lay a solid foundation for effective analysis. This understanding allows you to choose appropriate algorithms and techniques while avoiding common pitfalls associated with misinterpreting or mishandling temporal sequences.
In summary, understanding your time series data is a critical step in successful mining and analysis. By delving deep into its characteristics, trends, outliers, contextual factors, and quality, you can make more accurate predictions and uncover valuable insights. So, before embarking on any time series data mining project, remember to invest time in comprehending the data itself – it will pay off in the quality of your results.
Use appropriate algorithms
When it comes to time series data mining, using the appropriate algorithms is key to extracting meaningful insights and making accurate predictions. The choice of algorithm can greatly impact the quality and reliability of the results obtained.
One crucial consideration is the nature of the time series data itself. Is it seasonal? Does it exhibit a trend? Is it stationary or non-stationary? These characteristics will guide your algorithm selection.
For example, if your data exhibits a clear trend or seasonality, statistical methods like ARIMA or ETS can be effective in capturing these patterns. These models take into account historical values and use them to forecast future values while considering trends and seasonal fluctuations.
On the other hand, if your time series data has complex dependencies and long-term memory effects, machine learning algorithms such as recurrent neural networks (RNN) or long short-term memory networks (LSTM) can be powerful tools. These algorithms are designed to capture sequential patterns in data and are particularly useful when dealing with large datasets.
Additionally, consider the computational requirements and scalability of the algorithm. Some algorithms might be more computationally intensive than others, making them less suitable for large-scale datasets or real-time applications. It’s essential to strike a balance between accuracy and efficiency based on your specific needs.
Furthermore, don’t forget about ensemble methods. Combining multiple algorithms can often lead to improved performance by leveraging their individual strengths. Techniques like bagging or boosting can help reduce bias and variance in predictions, resulting in more robust models.
Lastly, keep in mind that no single algorithm is universally superior for all types of time series data mining tasks. It’s crucial to experiment with different algorithms, compare their performance using appropriate evaluation metrics, and choose the one that best suits your specific requirements.
In summary, using appropriate algorithms is vital for successful time series data mining. Consider the characteristics of your data, computational requirements, scalability needs, and explore ensemble methods when necessary. By selecting the right algorithms, you can unlock the full potential of your time series data and pave the way for accurate predictions and valuable insights.
Implement proper pre-processing steps
Implement Proper Pre-processing Steps: The Key to Unlocking Time Series Data Mining
Time series data mining is a powerful tool for extracting valuable insights from temporal sequences. However, before diving into the analysis, it is crucial to implement proper pre-processing steps. These steps ensure the accuracy and reliability of the results obtained from time series data.
One of the initial pre-processing steps is handling missing values. Time series data often contains gaps or missing observations due to various reasons such as sensor failures or incomplete data collection. Ignoring these missing values can lead to biased results and inaccurate predictions. Therefore, careful imputation techniques need to be applied to fill in these gaps, ensuring that the integrity of the temporal sequence is maintained.
Another important aspect of pre-processing is handling outliers and noise in the data. Outliers are extreme values that deviate significantly from the expected pattern, while noise refers to random fluctuations that obscure underlying trends or patterns. These anomalies can distort analysis results and lead to erroneous conclusions. Applying appropriate outlier detection algorithms and noise reduction techniques helps in cleaning up the data and improving its quality.
Furthermore, time series data often exhibits non-stationarity, meaning that statistical properties such as mean and variance change over time. This can make it challenging to uncover meaningful patterns or trends in the data. To address this issue, pre-processing steps like detrending or differencing are employed to remove non-stationarity and make the data more amenable for analysis.
Additionally, scaling and normalization are essential pre-processing steps for time series data mining. Scaling ensures that different variables within a dataset are on a similar scale, preventing any particular variable from dominating the analysis due to its larger magnitude. Normalization transforms variables into a common range (e.g., between 0 and 1), enabling fair comparisons between different features or datasets.
Lastly, feature engineering plays a significant role in pre-processing time series data. It involves selecting or creating relevant features that capture important characteristics of the temporal sequence. This step can include extracting statistical measures, time-based features, or domain-specific features that enhance the predictive power of the models used for analysis.
Implementing proper pre-processing steps is essential to ensure accurate and reliable results in time series data mining. By addressing missing values, handling outliers and noise, dealing with non-stationarity, scaling and normalizing the data, and performing feature engineering, we can unlock the true potential of time series analysis. These pre-processing steps lay a solid foundation for building robust models and uncovering valuable insights from temporal sequences.
In conclusion, pre-processing time series data is a critical step in the journey of mining valuable information from temporal sequences. By paying attention to these crucial pre-processing steps, we can enhance the accuracy and reliability of our analyses, leading to more informed decision-making in various domains where time plays a crucial role.
Consider using a sliding window approach
Consider Using a Sliding Window Approach: Enhancing Time Series Data Mining
Time series data mining involves analyzing sequential data points over time to uncover patterns and make predictions. One effective technique to improve the accuracy and efficiency of time series analysis is by employing a sliding window approach.
The sliding window approach involves dividing the time series data into smaller, overlapping segments or windows. Each window consists of a fixed number of consecutive observations. By sliding this window along the time series, we can analyze multiple subsets of the data, capturing temporal dependencies and patterns more effectively.
There are several benefits to using a sliding window approach in time series data mining. Firstly, it allows us to capture local patterns within the data. By analyzing smaller segments, we gain insights into short-term trends and fluctuations that may be masked when considering the entire time series as a whole.
Secondly, the sliding window approach enables us to incorporate temporal context into our analysis. By including past observations within each window, we account for the sequential nature of the data and capture dependencies between consecutive points. This is particularly useful for forecasting future values or detecting anomalies based on historical patterns.
Furthermore, using overlapping windows can provide additional information about transitions and changes in patterns over time. Overlapping windows ensure that each observation is included in multiple segments, allowing us to detect shifts or variations in behavior more accurately.
However, it is important to strike a balance between the size of the window and the amount of overlap. A smaller window size provides higher resolution but may overlook long-term trends, while a larger window size captures more global patterns but may miss local fluctuations. Similarly, too much overlap can lead to redundant information while too little overlap may result in missing important transitions.
In conclusion, incorporating a sliding window approach into time series data mining enhances our ability to uncover meaningful patterns and make accurate predictions. It allows for better capturing of local trends, incorporating temporal context, and detecting transitions over time. By carefully selecting the window size and overlap, we can optimize our analysis and gain deeper insights into the dynamics of the data.
So, next time you embark on a time series data mining journey, consider using a sliding window approach to unlock the hidden secrets within your temporal sequences.
Utilize ensemble methods
Utilize Ensemble Methods: Enhancing Time Series Data Mining
Time series data mining is a complex task that requires careful analysis and modeling techniques to extract meaningful insights. One effective approach to improve the accuracy and robustness of time series analysis is by utilizing ensemble methods.
Ensemble methods involve combining multiple models or algorithms to make more accurate predictions or classifications. The idea behind ensemble methods is that the collective wisdom of diverse models can outperform any single model on its own.
When it comes to time series data mining, ensembles can be particularly beneficial. Time series data often exhibits various patterns, trends, and complexities that may not be captured adequately by a single model. By combining multiple models, we can leverage their individual strengths and compensate for their weaknesses.
One popular ensemble method for time series data mining is the “bagging” technique. Bagging involves training multiple models on different subsets of the time series data through resampling techniques such as bootstrapping. Each model learns from a slightly different perspective, which helps reduce bias and increase overall accuracy.
Another ensemble method commonly used in time series analysis is “boosting.” Boosting focuses on sequentially training models in a way that emphasizes the misclassified instances from previous iterations. This iterative process allows subsequent models to focus more on difficult-to-predict patterns, improving overall performance.
Ensemble methods also offer opportunities for combining different types of models. For example, combining statistical approaches like ARIMA or exponential smoothing with machine learning algorithms such as random forests or neural networks can provide a comprehensive understanding of time series dynamics.
Moreover, ensemble methods enable us to assess uncertainty and make more reliable predictions. By considering the diversity of predictions generated by different models within an ensemble, we can estimate prediction intervals or confidence intervals, providing valuable insights into the reliability of our forecasts.
However, it’s important to note that implementing ensemble methods requires careful consideration. The choice of base models, their diversity, and the aggregation mechanism all play a crucial role in the effectiveness of the ensemble. Additionally, ensemble methods may introduce additional computational complexity and require more resources.
In conclusion, utilizing ensemble methods in time series data mining can enhance the accuracy and reliability of predictions. By combining multiple models, we can capture a broader range of patterns, improve generalization, and assess uncertainty. As time series data continues to grow in importance across various domains, leveraging ensemble methods becomes an essential tool for extracting valuable insights from temporal sequences.
Monitor performance metrics
When it comes to time series data mining, one essential tip is to monitor performance metrics. Monitoring the performance of your models and algorithms is crucial for ensuring accurate predictions and reliable insights.
Performance metrics provide valuable information about the effectiveness and efficiency of your time series data mining techniques. They help you evaluate the quality of your models and identify areas for improvement. By regularly monitoring these metrics, you can make informed decisions about refining your approach.
One commonly used performance metric for time series data mining is Mean Absolute Error (MAE). MAE measures the average difference between predicted values and actual values. A lower MAE indicates better accuracy in predicting future observations.
Another important metric is Root Mean Squared Error (RMSE). RMSE calculates the square root of the average squared difference between predicted and actual values. It provides a measure of how well your model captures the variability in the data.
Additionally, monitoring performance metrics like Precision, Recall, and F1-score can be valuable when dealing with anomaly detection in time series data. These metrics help evaluate how well anomalies are detected and classified by your algorithms.
Regularly tracking these performance metrics allows you to assess whether your models are performing optimally or if adjustments are needed. It helps you identify potential issues such as overfitting or underfitting, which can affect the reliability of your predictions.
Moreover, monitoring performance metrics over time enables you to detect any degradation in model performance. As new data becomes available, it’s crucial to ensure that your models continue to provide accurate results. By comparing current metrics with historical benchmarks, you can identify any deviations or shifts in performance that may require investigation.
In conclusion, monitoring performance metrics is a fundamental aspect of time series data mining. It enables you to evaluate model accuracy, detect anomalies effectively, and ensure consistent performance over time. By paying close attention to these metrics, you can fine-tune your approach and make confident decisions based on reliable insights from your time series data.
No Responses